DDD Markdown
要想通过DDD来分析Markdown,首先要做的就是找到标准:CommonMark Spec。
不过要说明的是,这个规范并没有“官方”一说。因为MD并没有官方标准,大家现在都是自已玩自己的,并没有一个组织负责统一标准。之所以选择这个规范,是因为这份规范给出了清晰的MD定义,里面清晰的介绍了MD这个领域里出现的名字和概念,将帮助我们理解MD这个领域。
对于MD用户而言,我们的需求简单明确。我们希望将创作的内容可以展示在浏览器上。但浏览器推荐的文件格式是HTML,虽然HTML语法不复杂,但写作体验并不好。因为标签的格式繁琐,标签有开始部分,还有结束部分。更要命的是创作者还得去理解其它和内容不相干的标签含义,像head, body之类的标签。这不仅增加了创作者的认知负担,还让打字过程变得繁琐,让创作者没法专注于内空创作,以及享受整个创作的过程。
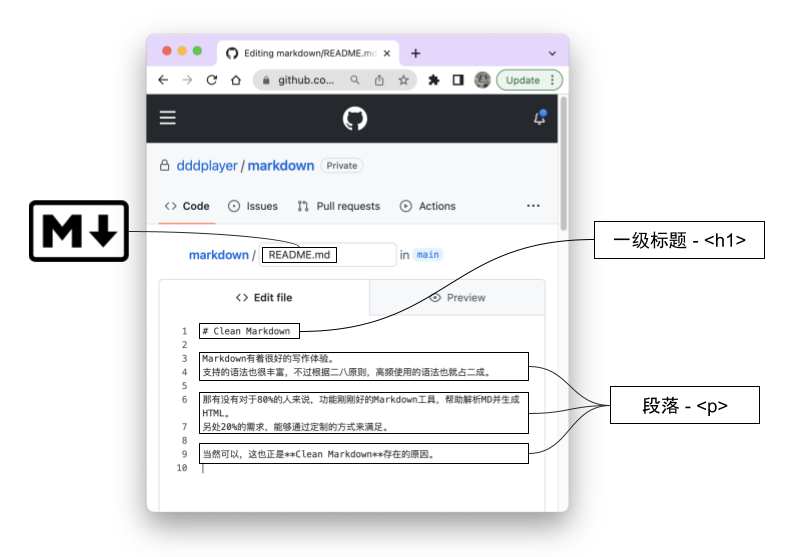
MD优雅的解决了这个问题,拿Clean markdown源码库中的README.md文件举例:
要想实现上面的效果,我们只需这样来写:
简洁明了。想要标题,就用‘#’起头。要想加粗就用‘**’来包裹内容。
再从MD文件解析的角度来看,哪果我们要将上面所书写的内容,转换成HTML,那我们首先就要读懂上面的MD内容:
再从真实渲染结果来验证一下我们上面的理解:
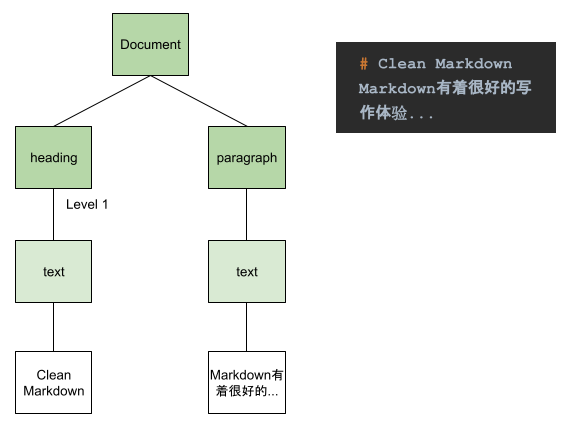
果然和我们上面分析的一样,一个标题h1,和三个段落p。
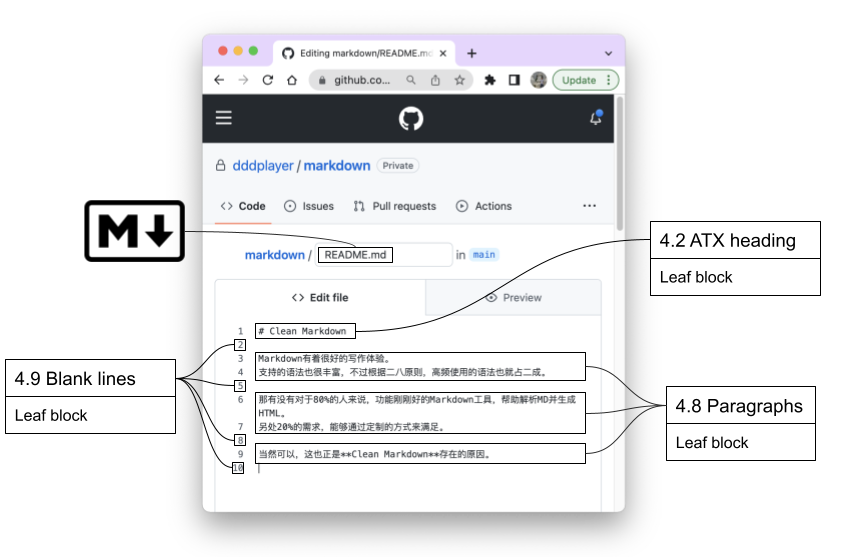
大家可能发现,我们在用语言对上面的渲染结果进行描述时,用的是HTML的语言,例如标签等。那描述MD的内容,我们又要用什么样的语言呢?这些正好是标准文档CommonMark Spec可以给我们提供的帮助。从讲述这个角度可以看出,领域专家的专,就体现在叫得上文档中每个元素的名字,而且知根知底:
可以看到,文档里所有的部分,都可以叫出名字,并且还归了类。像之前提到的标题和段落,就在规范中的第4.2和4.8章节,分别给出了定义,标题叫ATX heading,段落就是Parragraphs。我们还发现在4.9章节,对空白行也做出了定义,并取名Blank lines。
有了这些信息,我们就可以开始对Markdown这个领域开始建模了。
清楚这些概念后,我们要怎么让计算机读懂这个MD文件呢?用我们程序员的语言来说,就是要怎么解析MD文件呢?
幸运的是,CommonMark Spec在最后的附录中有给出一个解析策略:A parsing strategy。
解析分两个阶段:
在解析的过程中,又出现了两个领域概念,一个是块 - block,另一个是行内元素 - inline。同样在章节3中,有给出具体的定义:
也就是说,在规范里,我们将一个MD文件称之为document,document是由block序列组成的。 其中有的block可以包含其它block,有的block则包含inline相关的信息。 在规范中也有给这两种block相应的名称。 能包含其它block的block,我们管它们叫container block。 只包含inline信息的block,我们管它们叫leaf block。
其中container block有Block quotes, List items和Lists,这些block都可以包含其它block。
再看Leaf blocks,有Setext headings, Indent code blocks, Paragraphs等等。 这些leaf blocks可能包含inlines,如Links, Images, Textual content等等。
这样我们就可以将上面的文本信息转换成相应的block和inline了:
为了能让交付团队和业务代表高效沟通,我们希望DDD能帮助我们产出一套通用语言。不论什么角色,对同一个概念或名词的理解完全一致,这样可以帮助大大提升沟通的效率和减少项目应信息失真而带来的风险。为了帮助交付团队实现这些领域服务,我们还需要用统一语言构建出一套领域模型。这样所有的领域知识将有效的转换成代码,让业务语言、项目语言和机器语言高度一致。
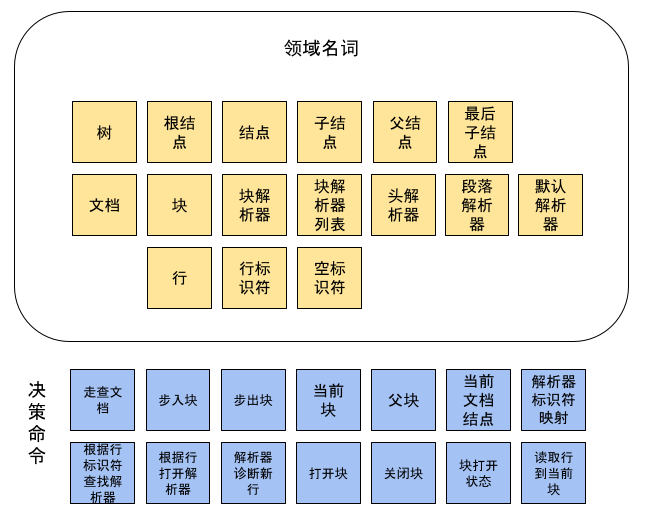
为了理解这个领域,我们需要邀请到该领域的专家,和我们一起梳理。上面的CommonMark Spec正好就承担了这一角色。根据规范所描述的解析策略,我们可以基于此先梳理出解析流程中出现的关键领域事件。有了领域事件后,我们就可以识别出决策命令和领域名词。也就是由谁做了什么样的操作,产生了哪些事件。而领域名词又能帮助我们分析出领域上下文,这将有助于我们理解领域中这些概念之间的关联关系。这些关联关系正是构建领域模型所需要的基本信息。
接下来,让我们按照这个思路实际操作一遍。这其中用到了下面的建模语言:
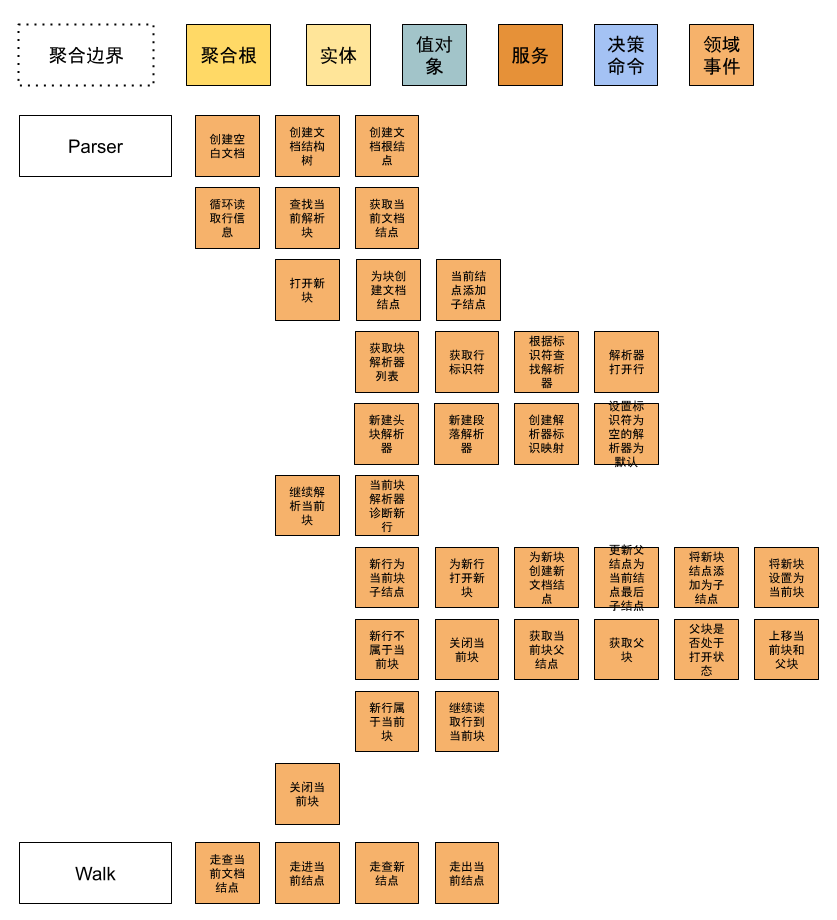
按照CommonMark Spec中描述的解析流程,我们可以得到以下领域事件:
为了把一个Markdown文件转换成一个HTML文件。其实需要两大步,一是解析Markdown源文件,另一步是通过走查源文件解析结点,渲染出HTML文件。为了方便大家理解DDD建模流程,我们将专注在第一步,也就是文档解析上面。
有了领域事件后,我们就能知道在这个领域中,发生了哪些事情。可以帮助我们分析出谁响应了什么样的请求,处理这些请求的过程中,产生了这些事件。这其中的“谁”通常就是领域名词,也就是干活的那个人,而“请求”来自于调用方,是当前对象可以提供的服务,也就是模型中的决策命令。所以,在这一步中,可以帮助我们识别出具体干活的对象,及它需要具备哪些能力。
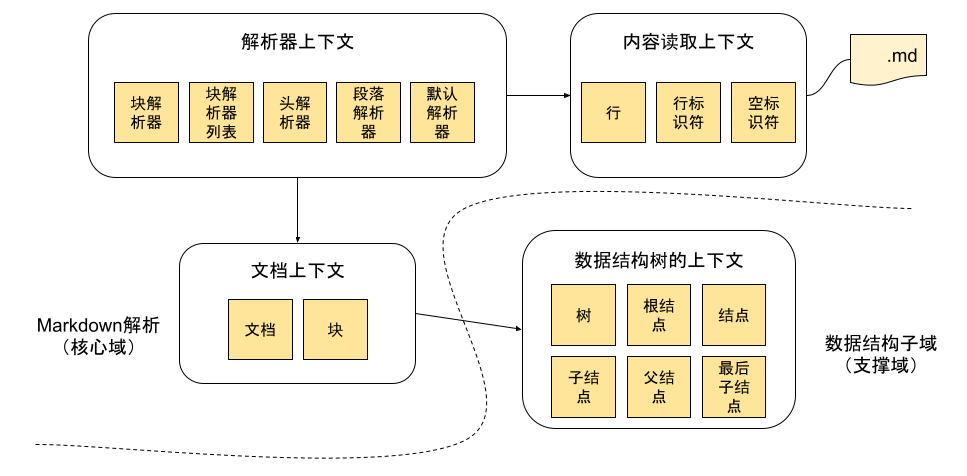
想要把事情干成,除了要知道需要哪些能力,要找什么样的人,还需要知道如何把大家高效组织起来。哪些是我们的核心能力,必需要重金搞入,亲力亲为。又有哪些能力不需要自己从零开始,把这些事交给专业的人。
我们发现,Markdown解析将是我们的核心域,要想在市场上存活,我们需要在把这一块投入主要精力。而我们依赖的能力有数据结构 - 树。但用什么样的树,并不能让我们有效区分于其它Markdown解析器,我们完全可以把这一块交给合作方来完成。
领域专家和交付团队都理解了。现在轮到计算机了。
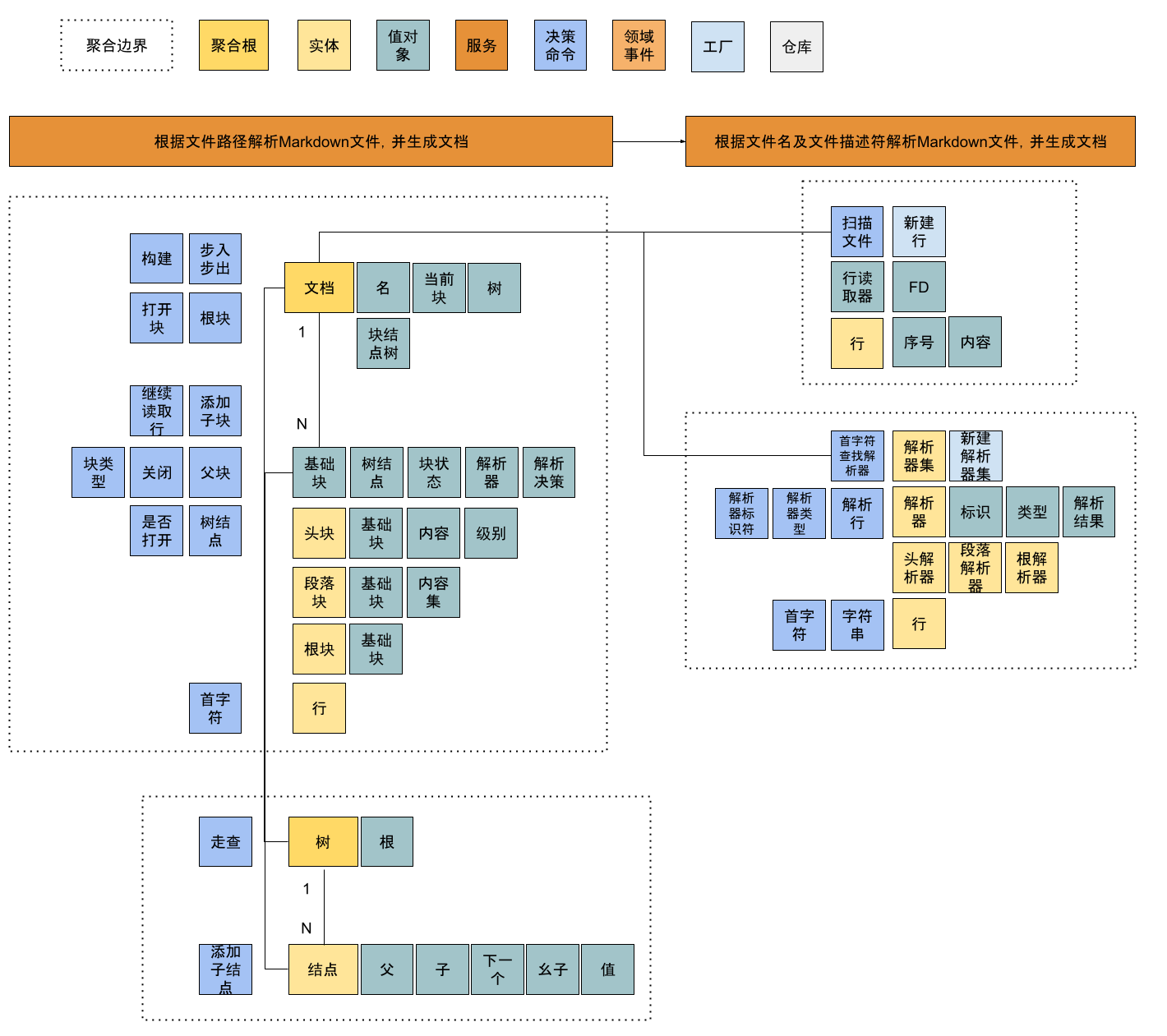
对领域模型的要求是程序员可以参照模型直接实现代码,这样才能让计算机和咱们也统一了语言,可以高效沟通了。
纸上得来终觉浅,既要理论,也要实践。
按照模型编码过程中,模型的细节变得越来越丰富,小方块的颜色也是变来变去。因为模型的变动和Golang不能循环引用的规则,源码库中的文件也跟着移来移去。
可以看出模型和语言是相互作用的,并不是一方完全主宰另一方。
从领域模型的视野出发,我们能很容易识别出领域中主要的概念,但有一些隐藏的知识并不能在一开始就识别出来。这就需要在源码实现的过程中推敲出这些细节,和团队及领域专家反复沟通。
从源码实现的角度出发,要想实现领域模型,我们还需要借助于编程领域的知识,像数据结构、架构设计等等。这也是整套模型想要高效运行所必需的信息。
这样来看,模型中需要包含业务领域概念,也需要包含技术领域概念。这有助于帮助业务成员理解技术的复杂度,也能帮助技术人员理解业务的逻辑。这也正是DDD所追求的统一语言。